Connector goodness from Airbyte E2E lineage
Part 6 reusing existing off-the-shelf connectors to various data sources for ingestion
Welcome 😄 to this blog series about the modern data stack ecosystem.
post series overview
This is the 6th part in this series of blog posts about the modern data stack. It is an example of how to use the Software-Defined Asset APIs alongside Modern Data Stack tools (specifically, Airbyte and dbt).
DBT](https://docs.getdbt.com/docs/introduction) is used for transformation of data, but the ingest is missing. Airbyte offers connectors to various systems as an open source competitor to Fivetran or Stichdata. Together the E2E lineage of ingestion and transformation and perhaps further python-based machine learning steps in the pipeline can be modeled.
This example is based on https://github.com/dagster-io/dagster/tree/master/examples/modern_data_stack_assets which is mentioned in https://dagster.io/blog/software-defined-assets.
The other posts in this series:
- overview about this whole series including code and dependency setup
- basic introduction (from hello-world to simple pipelines)
- assets: turning the data pipeline inside out using software-defined-assets to focus on the things we care about: the curated assets of data and not intermediate transformations
- a more fully-fledged example integrating multiple components including resources, an API as well as DBT
- integrating jupyter notebooks into the data pipeline using dagstermill
- working on scalable data pipelines with pyspark
- ingesting data from foreign sources using Airbyte connectors
- SFTP sensor reacting to new files
preparatory steps
A running postgres database and airbyte instance are mandatory to follow along with the example.
A docker-compose.yaml file is included in the code repository here.
It contains all the neccessary containers.
You can start one using docker by executing:
cd modern_data_stack_assets
docker-compose up
- Postgres is avaiable on: localhost:5432
- Airbyte is available on: http://localhost:8000
Furthermore in Airbyte the connectors need to be set up and dummy data needs to be loaded into the database.
Basically the user and password need to be specifiy to connect to the database:
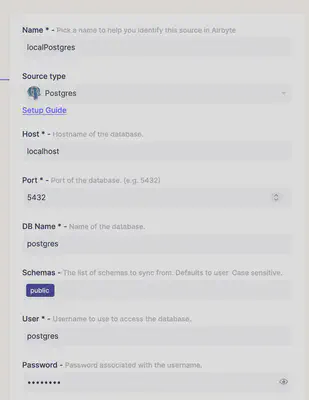
To simplify this process a script is included which fully automates these steps:
conda activate
python -m modern_data_stack_assets.setup_airbyte
# Created users table.
# Created orders table.
# Created Airbyte Source: ...
# Created Airbyte Destination: ...
# Created Airbyte Connection: <<TOKEN>>
You need to register the token in the constants file located here.
graph integrating airbyte, dbt and python code
Then, using any database tool of your choice connect to the database.
The user and password (docker/docker) is found in the docker-compose.yaml file.
Execute:
CREATE DATABASE postgres_replica;
the workflow
The dummy workflow is:
- reading data from one postgres database and replicating into a second one named:
postgres_replica - calculating statistics and enrichments
- finally feeding data to a simple statistical model
To view the job graph go to dagit.
In dagit reload the current modern_data_stack_assets workspace and switch to the Assets job in dagit.
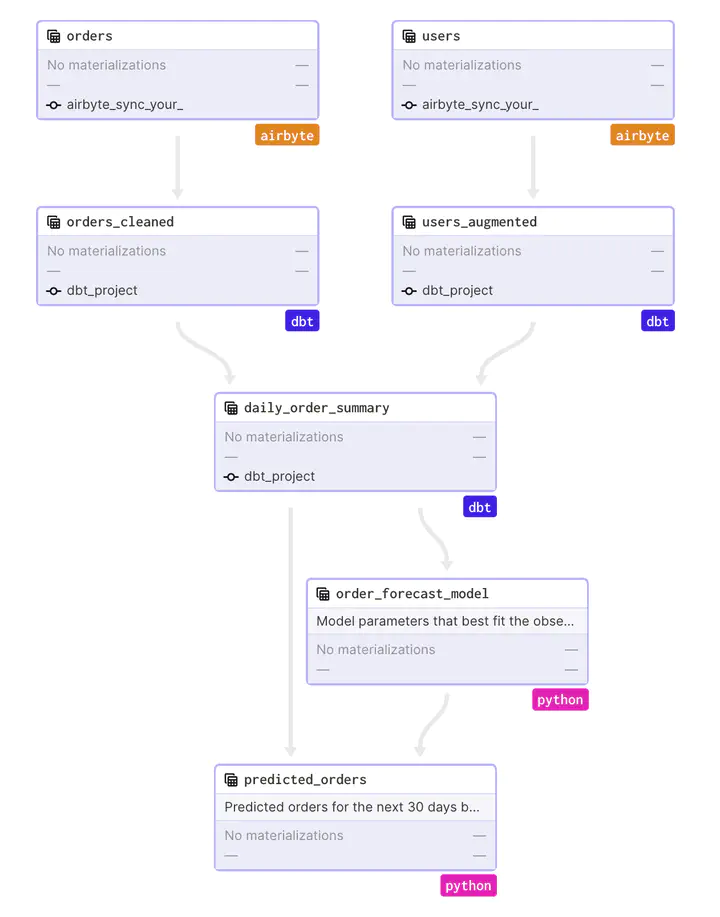
The lineage will look like this:
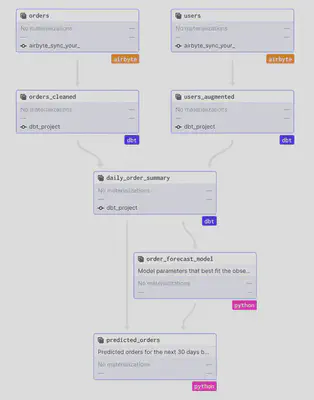
Immediately it becomes apparent how the various tools which could potentially become a silo for themselves are neatly integrated in the data pipeline orchestrated by dagster. Stale assets are immediately clear and also the lineage can be viewed directly - from the source system to the model.
For each asset statistics are tracked and metadata like the details about the SQL tables are tracked from DBT.
The lineage of assets can be viewed selectively for up- or downstream assets (or in full).
one further example
A second example from https://airbyte.com/recipes/orchestrate-data-ingestion-and-transformation-pipelines can be found here: https://github.com/OwenKephart/airbyte_demo
summary
By interfacing dagster with a data ingestion tool like Airbyte the E2E lineage from sourcing the data until the final data asset is served as a product to the business user can be tracked. Furthermore, this allows to tap into the ecosystem of ready-made open source connectors of Airbyte for efficient data ingestion.
Georg Heiler
Researcher & data scientist
My research interests include large geo-spatial time and network data analytics.